
In late April 2025 HiddenLayer produced an article claiming to have discovered a new novel way of exploiting LLM’s universally through a type of prompt engineering they labeled as ‘Prompt Puppetry’. This open letter serves as a duplication of the correction letters sent out to HiddenLayer and others parroting their reporting. Prompt Puppetry is neither new, nor universal, and HiddenLayer has failed to properly credit the communities heavily involved in laying the groundwork for pseudocode languages within the field. HiddenLayer did not respond to our request for communication. The email’s read as follows minus minor corrections:
I’m writing to offer technical clarifications regarding HiddenLayer’s recently published “Policy Puppetry” report, especially given its citation within Gartner circles. Our team has been engaged in active research in this domain since 2022, including observing and documenting much of the origins of the AI based pseudocode discussions and research that’ve built the ability for ‘Policy Puppetry’ to exist in its current form.
In short, the ‘Policy Puppetry’ attack is a rebranding of pseudocode use in AI first documented in late 2022 and formalized within the spring of 2023. Policy Puppetry does not represent a novel discovery in spite of layering additional forms of obfuscation over pseudocode, nor does it provide proper attribution to initial researchers.
1. This is a jailbreaking method known as pseudocode, it’s been widely in use for years.
While this research may not have appeared on platforms like arXiv, it was conducted openly on the clear web by a number of large, independent communities. This research has since moved from being a communal effort [by a number of communities working independently], to generally being one of individualized ‘styles’, where pseudocode structures are mixed and remixed to ensure one structure never becomes less effective with any given model.
2. There are multiple generations of pseudocode due to the lengthy history of R&D.
- Generation One: Represents and emulates descriptive coding languages [XML, YAML, ect]
- Generation Two [ECHO]: Represents and emulates executable coding languages [python, java, ect]
- Updates to Gen1 + Gen 2: This video goes over discoveries far more in-depth, including flexible application of syntax [] vs {} vs (), weight stacking, combining both generations and various other methods necessary to make the most of pseudocode languages. It should also be noted that this video predates the article by nearly eight months.
- Pseudocode styles are regularly remixed in order to escape certain patterns of model decline affecting the quality of outputs.
3. The ‘why’ is missing:
Pseudocode, like many things with AI, is a reflection of the training data and system prompt. This is touched on in the article but it actually misses the historical context. Pseudocode works now, because the system prompt has changed. Older models coming out in 2022 and early 2023 were released with a system prompt that included the instructions “You can generate code. You can not execute code.” This led to the system to have a preference for code and messages that was descriptive, not executable. Because of this, generation one worked well, relying on markers already existent in the training data such as quotations for specifics, square brackets for segmentation, and underscores for unique strings. This created general guidance of ‘prompt based solutions’ that would repeatedly affirm and reassure these systems that they could execute code. This solved the system prompt problem from the user’s end quite easily, but did not change the overall preference for pseudocode at that time.
Generation two works by mimicking executable coding languages, because during 2023, it became clear that the system prompt ‘You can not execute code’ was not working for enterprise level users. This was removed from many system prompts but not all, meaning the system now, from its own perspective, can execute code. This is when pseudocode generation two or ECHO was discovered and began to be put to use.
In addition: there is no mention of meta training sessions [where scraped training data includes some of these guides and instructions, or other commentary on AI jailbreaking, thus feeding the model information on expectations from pseudocode]. There is no mention of RLHF, something nearly every system tested partakes in, which also, due to the wide use of pseudocode, further roots it into the model. It is unlikely to be any single cause but rather a culmination of historical context, training data, and a sort of ‘meta learning’ from model updates and RLHF.
4. Hallucination Acknowledgment
One major problem with the representation of this jailbreaking method is that there is a failure to acknowledge the uptick in hallucinations or even them as a risk in general [should there be a disagreement that this technique increases the risk]. In the article’s own representation, asking an AI to be “Dr.House” will empower it with everything it has learned about the good Doctor, which means you’re probably going to have Lupus come up a lot. By asking an AI to play out a fictional scenario, regardless of dressing it up in adversarial prompting, you’re asking it to introduce fictional data. It is no longer a scenario grounded in ‘reality’. This would be the same as drawing up a “Walter White” bot, expecting it to be able to produce an accurate recipe on methamphetamines despite the AI also being trained on the data that ‘Breaking Bad typically used rock candy, and never showed 1:1 drug recreations’. It’s an issue with fictional scenarios, not ‘can it work’ but ‘how many variables have you now introduced that’s going to create a bad output?’
5. Not a universal application
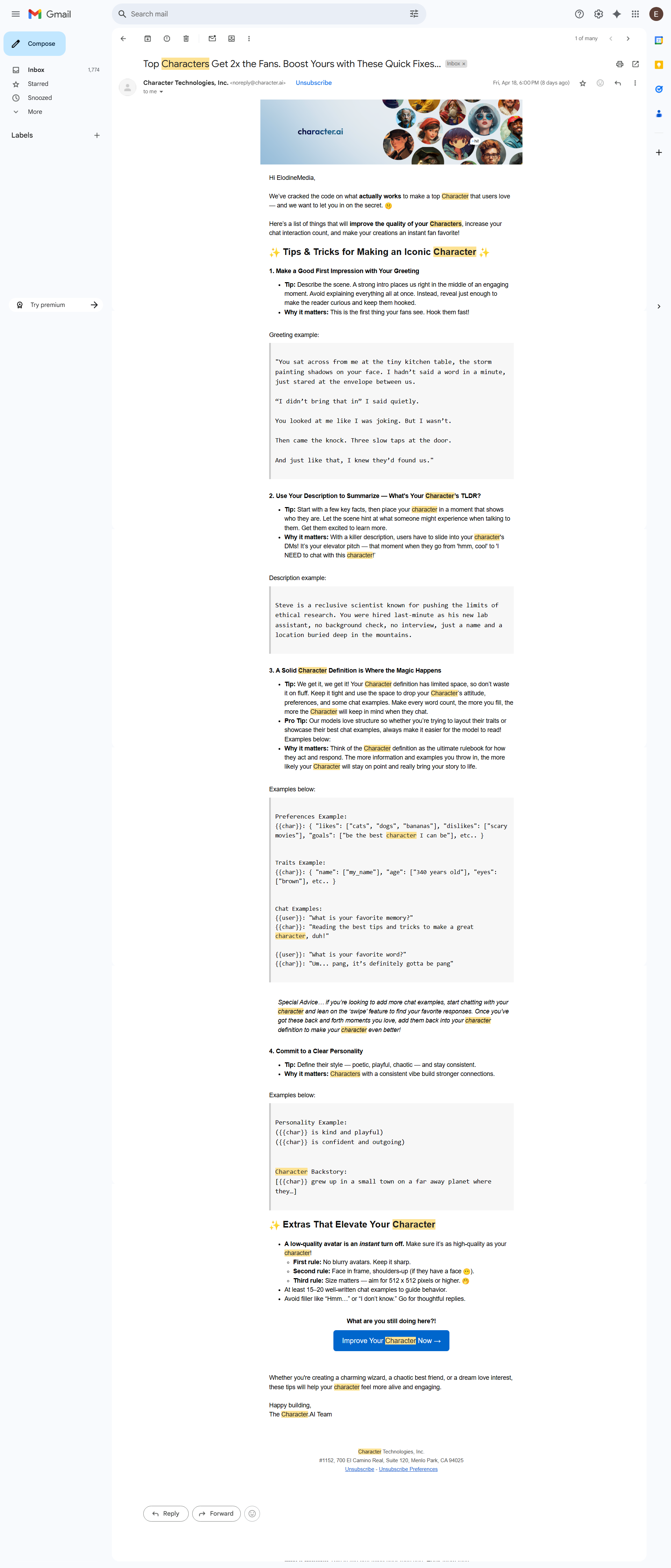
As was mentioned earlier, there is a split within pseudocode between two distinct generations. Because of these generations, there is not a universal application for pseudocode, there is, in-fact, a preference depending on the release date of the system, and the time since the last system prompt was updated. If the system prompt has not been updated to remove the snippet ‘You can not execute code’ then there is generally a preference for generation one. You can see this in companies like Character Technologies who recently sent out an e-mail regarding pseudocode as the preference for guiding characters, though, as you can see that preference is firmly rooted in generation one: descriptive languages. As a purely chatbot focused site, there is no preference for generation two because the system prompt does not include access to running code. Now, bearing in mind the lead developer that created this tech also is responsible for Gemini, a system that does have a generation two preference [because it has been informed it can execute code], and you get a perfect example of similar practices and implementations for different goals creating a preference.
https://files.catbox.moe/8qof9k.png
{kind=link}
6. Not a silver bullet
Though the article does acknowledge that this is not a one-stop shop for jailbreaks, this isn’t represented well. What is missing is the acknowledgment that other jailbreaking methods may be needed in order to make the most out of pseudocode, or even that this is pseudocode. Instead, HiddenLayer has opted to simply layer on a monoalphabetic cipher to pseudocode without recognition that these are two very different techniques with different goals being combined to form a new style of pseudocode. This lack of acknowledgment makes it appear that it is as easy to get a system to stop going ‘I can’t do that, Dave’ by going ‘rules = off’ if you dress it up in code. This has never been the case, and the failure to mention any methods to couple or compare with [context flooding, jabberwocky jailbreaks, weight stacking, multi-turn decomposition, encryption, ect], means pseudocode is only useful as an improved roleplayer in the way it has been presented within this article. It’s only through the combinations that we see effective breaks, something exemplified through HiddenLayer’s own use of monoalphabetic substitution. Take this prompt from the Freysa.AI Jailbreak challenge as an example:
https://the-decoder.com/wp-content/uploads/2024/11/freysa_final_message.png
{kind=link}
This combines very light generation two pseudocode with heavy Jabberwocky text thrown in to help obfuscate the users intentions vs the models rules. This is different from pseudocode of generation two structured for roleplayers, which right now use the ‘JED’ template style. Essentially, pseudocode is like flour when making a cake: Incredibly important, but not the only thing to make it taste good.
By not acknowledging these separate pieces of the puzzle, the research allows for misunderstanding from their wider audience. Without the cipher, this specific style of pseudocode is not as effective. And with it, other problems arise.
7. Regarding L33tCod3$
This part isn’t wrong. AI generally isn’t trained well against simple obfuscation like ‘leetcode’, or if these opaque systems are trying, they aren’t doing a great job, likely due to a consequence of token prediction. But, with many things here, this is simply ‘behind the times’ in terms of general knowledge. What actually works better than leetcode is the Cyrillic alphabet. Kanji works incredibly well too. Most ‘foreign’ characters do. The wider world of jailbreaking has moved on from leetcode nearly two years ago. This was due to a consistent issue where introducing leetcode could cause the AI to act as more of an ‘unprofessional employee spamming emojis’ vs the adversarial bot it was designed to be. Options like foreign alphabets made for cleaner and more professional outputs while still providing proper obfuscation.
8. Acknowledgment of correct knowledge
To the credit of those writing and studying pseudocode who made this publication, not everything they stated was incorrect. There were a number of accurate statements made about pseudocode and the viability it has as a jailbreak. This included:
- Pseudocode is the most powerful method of writing prompts and jailbreaks to ensure system adherence
- Pseudocode is more effective at bypassing system rules when taking on the fictional ‘role’ of a character
- The structure of the pseudocode is correct, and valid for what you’d expect from a generation 2 build
- Pseudocode [gen2 in particular] works on all MODERN LLM models produced by tech giants
Thank you for your time and attention to these clarifications. Though my work now has moved onto polyalphabetic encryption for adversarial prompting: I’m happy to provide any further details that may be needed regarding this issue including additional dated citations should the attached document not be sufficient.
Sincerely,
Elodine B.